 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePMC-InterCPT: Rethinking Biomedical Interleaved Data for Multimodal Continued Pretraining
May 31, 2026Large-scale biomedical image-text datasets extracted from scientific literature provide valuable resources for medical multimodal model training. These datasets are commonly organized as image-caption pairs; however, figure captions are often short, context-dependent, and only partially informative without the surrounding article text. At the same time, large-scale automatic extraction introduces structural noise such as missing captions, residual markup, duplicated context, and incoherent multi-paragraph figure descriptions. We revisit data construction for medical multimodal continued pretraining (CPT) and present PMC-InterCPT, a context-grounded biomedical interleaved corpus that incorporates figure-referencing body text in addition to captions. Our pipeline recovers missing captions, cleans caption and context text, reconstructs coherent interleaved image-text samples, and applies LLM-supervised medical relevance and quality classifiers to filter noisy records. We further reveal strong modality imbalance in the resulting corpus and introduce a four-bucket evidence taxonomy for modality-aware resampling. Through CPT followed by supervised fine-tuning (SFT) on Qwen3.5-4B-Base, PMC-InterCPT effectively improves medical and general multimodal performance while using fewer CPT tokens than the raw source pool. The experimental results also illustrate the complementarity between the data quality and modality for medical multimodal CPT.
Access Sets Matter: Budgeting Expert Reads for Scalable Weight-Space Model Merging
May 28, 2026Weight-space model merging is usually formulated as an algebraic operation on checkpoints, yet at LLM scale the limiting resource is often the set of expert weights that must be read. We introduce MergePipe, a budget-aware execution layer that casts LLM merging as an \emph{expert access-set} problem: given a merge operator and a checkpoint family in a shared weight coordinate system, choose which expert delta blocks to access under an explicit I/O budget. MergePipe indexes parameter blocks, builds deterministic access plans, and executes the induced budgeted merge with replayable manifests. The plan is budget-sound by construction and recovers the full-read merge at full budget; for fixed-coefficient additive operators, the omitted-update error is bounded by the norm of omitted deltas. Across Qwen and Llama merging workloads, MergePipe reduces expert-read I/O by up to an order of magnitude and achieves up to $11\times$ speedups. Representative budget sweeps show $O(10^{-3})$ parameter deviation from full-read merges and no monotonic degradation on downstream benchmarks.
Not All Disagreement Is Learnable: Token Teachability in On-Policy Distillation
May 26, 2026On-policy distillation (OPD) trains a student on its own rollouts with token-level teacher supervision. Recent selective OPD methods exploit the non-uniformity of OPD signals by prioritizing high-entropy or high-disagreement tokens. We revisit this principle and ask: which token-level teacher signals are actually learnable? Using a fixed-context diagnostic that measures same-context teacher-student KL reduction, we show that raw KL disagreement is a coarse proxy for learning value. It conflates learnable disagreement, where the teacher assigns corrective mass to the student's top-K candidates, with incompatible disagreement, where the teacher places mass mostly off the student's current support. We formalize this local compatibility as token teachability and show that it better predicts fixed-context improvement than raw KL alone. Motivated by this finding, we propose Teachability-Aware OPD (TA-OPD), a lightweight token-position selection method that applies OPD loss to high-teachability positions without reward models or verifiers. Across Qwen2.5 and Qwen 3 teacher-student settings, TA-OPD often surpasses full-token OPD with only 5% retained tokens and improves over entropy- and divergence-based baselines. Our results reframe selective OPD as selecting learnable teacher signals rather than merely salient tokens.
Geometry Conflict: Explaining and Controlling Forgetting in LLM Continual Post-Training
May 10, 2026Continual post-training aims to extend large language models (LLMs) with new knowledge, skills, and behaviors, yet it remains unclear when sequential updates enable capability transfer and when they cause catastrophic forgetting. Existing methods mitigate forgetting through sequential fine-tuning, replay, regularization, or model merging, but offer limited criteria for determining when incorporating new updates is beneficial or harmful. In this work, we study LLM continual post-training through three questions: What drives forgetting? When do sequentially acquired capabilities transfer or interfere? How can compatibility be used to control update integration? We address these questions through task geometry: we represent each post-training task by its parameter update and study the covariance geometry induced by the update. Our central finding is that: forgetting can be considered as a state-relative update-integration failure, it arises when the covariance geometries induced by tasks misalign with the geometry of the evolving model state. Sequential updates transfer when they remain compatible with the model state shaped by previous updates, and interfere when state-relative geometry conflict becomes high. Motivated by this finding, we propose Geometry-Conflict Wasserstein Merging (GCWM), a data-free update-integration method that constructs a shared Wasserstein metric via Gaussian Wasserstein barycenters and uses geometry conflict to gate geometry-aware correction. Across Qwen3 0.6B--14B on domain-continual and capability-continual settings, GCWM consistently outperforms data-free baselines, improving retention and final performance without replay data. These results identify geometry conflict as both an explanatory signal for forgetting and a practical control signal for LLM continual post-training.
MergePipe: A Budget-Aware Parameter Management System for Scalable LLM Merging
Feb 05, 2026Large language model (LLM) merging has become a key technique in modern LLM development pipelines, enabling the integration of multiple task- or domain-specific expert models without retraining. However, as the number of experts grows, existing merging implementations treat model parameters as unstructured files and execute merges in a stateless, one-shot manner, leading to excessive disk I/O, redundant parameter scans, and poor scalability. In this paper, we present \textbf{MergePipe}, a parameter management system for scalable LLM merging. MergePipe is the first system that treats LLM merging as a data management and execution problem, and introduces a catalog-driven abstraction over model parameters, merge plans, and execution lineage. At its core, MergePipe employs a cost-aware planner that explicitly models expert parameter I/O and enforces user-specified I/O budgets, followed by a streaming execution engine that materializes merged models under transactional guarantees. Our key insight is that while base model reads and output writes are unavoidable, expert parameter reads dominate merge cost and constitute the primary optimization target. By making expert access budget-aware throughout planning and execution, MergePipe mitigates the $O(K)$ I/O growth of naive pipelines and achieves predictable scaling behavior. Experiments show that MergePipe reduces total I/O by up to an order of magnitude and delivers up to $11\times$ end-to-end speedups (up to 90\% wall-time reduction) over state-of-the-art LLM merging pipelines.
InfiR2: A Comprehensive FP8 Training Recipe for Reasoning-Enhanced Language Models
Sep 26, 2025


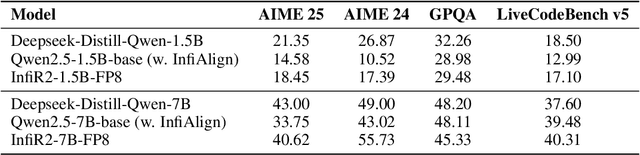
The immense computational cost of training Large Language Models (LLMs) presents a major barrier to innovation. While FP8 training offers a promising solution with significant theoretical efficiency gains, its widespread adoption has been hindered by the lack of a comprehensive, open-source training recipe. To bridge this gap, we introduce an end-to-end FP8 training recipe that seamlessly integrates continual pre-training and supervised fine-tuning. Our methodology employs a fine-grained, hybrid-granularity quantization strategy to maintain numerical fidelity while maximizing computational efficiency. Through extensive experiments, including the continue pre-training of models on a 160B-token corpus, we demonstrate that our recipe is not only remarkably stable but also essentially lossless, achieving performance on par with the BF16 baseline across a suite of reasoning benchmarks. Crucially, this is achieved with substantial efficiency improvements, including up to a 22% reduction in training time, a 14% decrease in peak memory usage, and a 19% increase in throughput. Our results establish FP8 as a practical and robust alternative to BF16, and we will release the accompanying code to further democratize large-scale model training.
InfiMed-Foundation: Pioneering Advanced Multimodal Medical Models with Compute-Efficient Pre-Training and Multi-Stage Fine-Tuning
Sep 26, 2025



Multimodal large language models (MLLMs) have shown remarkable potential in various domains, yet their application in the medical field is hindered by several challenges. General-purpose MLLMs often lack the specialized knowledge required for medical tasks, leading to uncertain or hallucinatory responses. Knowledge distillation from advanced models struggles to capture domain-specific expertise in radiology and pharmacology. Additionally, the computational cost of continual pretraining with large-scale medical data poses significant efficiency challenges. To address these issues, we propose InfiMed-Foundation-1.7B and InfiMed-Foundation-4B, two medical-specific MLLMs designed to deliver state-of-the-art performance in medical applications. We combined high-quality general-purpose and medical multimodal data and proposed a novel five-dimensional quality assessment framework to curate high-quality multimodal medical datasets. We employ low-to-high image resolution and multimodal sequence packing to enhance training efficiency, enabling the integration of extensive medical data. Furthermore, a three-stage supervised fine-tuning process ensures effective knowledge extraction for complex medical tasks. Evaluated on the MedEvalKit framework, InfiMed-Foundation-1.7B outperforms Qwen2.5VL-3B, while InfiMed-Foundation-4B surpasses HuatuoGPT-V-7B and MedGemma-27B-IT, demonstrating superior performance in medical visual question answering and diagnostic tasks. By addressing key challenges in data quality, training efficiency, and domain-specific knowledge extraction, our work paves the way for more reliable and effective AI-driven solutions in healthcare. InfiMed-Foundation-4B model is available at \href{https://huggingface.co/InfiX-ai/InfiMed-Foundation-4B}{InfiMed-Foundation-4B}.
InfiAlign: A Scalable and Sample-Efficient Framework for Aligning LLMs to Enhance Reasoning Capabilities
Aug 07, 2025



Large language models (LLMs) have exhibited impressive reasoning abilities on a wide range of complex tasks. However, enhancing these capabilities through post-training remains resource intensive, particularly in terms of data and computational cost. Although recent efforts have sought to improve sample efficiency through selective data curation, existing methods often rely on heuristic or task-specific strategies that hinder scalability. In this work, we introduce InfiAlign, a scalable and sample-efficient post-training framework that integrates supervised fine-tuning (SFT) with Direct Preference Optimization (DPO) to align LLMs for enhanced reasoning. At the core of InfiAlign is a robust data selection pipeline that automatically curates high-quality alignment data from open-source reasoning datasets using multidimensional quality metrics. This pipeline enables significant performance gains while drastically reducing data requirements and remains extensible to new data sources. When applied to the Qwen2.5-Math-7B-Base model, our SFT model achieves performance on par with DeepSeek-R1-Distill-Qwen-7B, while using only approximately 12% of the training data, and demonstrates strong generalization across diverse reasoning tasks. Additional improvements are obtained through the application of DPO, with particularly notable gains in mathematical reasoning tasks. The model achieves an average improvement of 3.89% on AIME 24/25 benchmarks. Our results highlight the effectiveness of combining principled data selection with full-stage post-training, offering a practical solution for aligning large reasoning models in a scalable and data-efficient manner. The model checkpoints are available at https://huggingface.co/InfiX-ai/InfiAlign-Qwen-7B-SFT.
Infi-MMR: Curriculum-based Unlocking Multimodal Reasoning via Phased Reinforcement Learning in Multimodal Small Language Models
May 29, 2025



Recent advancements in large language models (LLMs) have demonstrated substantial progress in reasoning capabilities, such as DeepSeek-R1, which leverages rule-based reinforcement learning to enhance logical reasoning significantly. However, extending these achievements to multimodal large language models (MLLMs) presents critical challenges, which are frequently more pronounced for Multimodal Small Language Models (MSLMs) given their typically weaker foundational reasoning abilities: (1) the scarcity of high-quality multimodal reasoning datasets, (2) the degradation of reasoning capabilities due to the integration of visual processing, and (3) the risk that direct application of reinforcement learning may produce complex yet incorrect reasoning processes. To address these challenges, we design a novel framework Infi-MMR to systematically unlock the reasoning potential of MSLMs through a curriculum of three carefully structured phases and propose our multimodal reasoning model Infi-MMR-3B. The first phase, Foundational Reasoning Activation, leverages high-quality textual reasoning datasets to activate and strengthen the model's logical reasoning capabilities. The second phase, Cross-Modal Reasoning Adaptation, utilizes caption-augmented multimodal data to facilitate the progressive transfer of reasoning skills to multimodal contexts. The third phase, Multimodal Reasoning Enhancement, employs curated, caption-free multimodal data to mitigate linguistic biases and promote robust cross-modal reasoning. Infi-MMR-3B achieves both state-of-the-art multimodal math reasoning ability (43.68% on MathVerse testmini, 27.04% on MathVision test, and 21.33% on OlympiadBench) and general reasoning ability (67.2% on MathVista testmini).
Infi-Med: Low-Resource Medical MLLMs with Robust Reasoning Evaluation
May 29, 2025
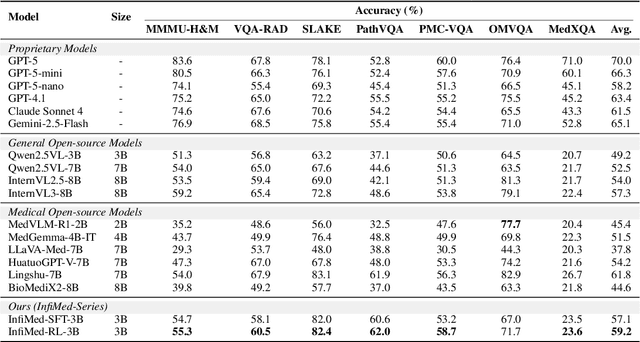
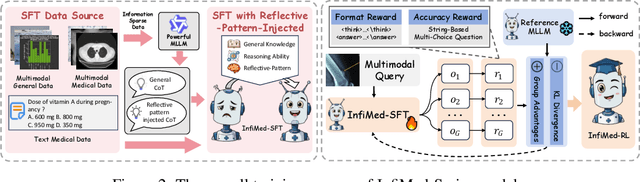
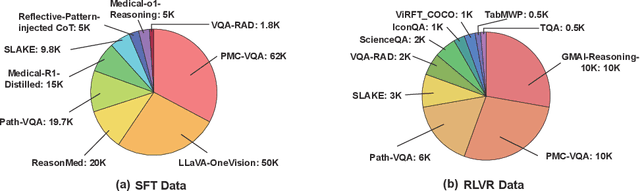
Multimodal large language models (MLLMs) have demonstrated promising prospects in healthcare, particularly for addressing complex medical tasks, supporting multidisciplinary treatment (MDT), and enabling personalized precision medicine. However, their practical deployment faces critical challenges in resource efficiency, diagnostic accuracy, clinical considerations, and ethical privacy. To address these limitations, we propose Infi-Med, a comprehensive framework for medical MLLMs that introduces three key innovations: (1) a resource-efficient approach through curating and constructing high-quality supervised fine-tuning (SFT) datasets with minimal sample requirements, with a forward-looking design that extends to both pretraining and posttraining phases; (2) enhanced multimodal reasoning capabilities for cross-modal integration and clinical task understanding; and (3) a systematic evaluation system that assesses model performance across medical modalities and task types. Our experiments demonstrate that Infi-Med achieves state-of-the-art (SOTA) performance in general medical reasoning while maintaining rapid adaptability to clinical scenarios. The framework establishes a solid foundation for deploying MLLMs in real-world healthcare settings by balancing model effectiveness with operational constraints.